" Transport evolution from one technology that is being phased out to another technology is a scientific thought process and is not governed by a raw abhorrence of the technology that is phasing out"
------ A recent conversation output
My dear friends of the transmission fraternity,
SDH (Synchronous Digital Hierarchy), a technology that actually governed the transport networks of the operators for more than 3 decades is slowly but steadily phasing out. This is plainly due to the fact that the services are moving more towards a packetized format than being a TDM oriented service.
I NEED ADVANCED FEATURES:(Wrong Reason)
However, if this statement is true, one thing is also true that Ethernet is very well able to ride over the SDH as EoSDH with or without MPLS capabilities making use of the existing back-haul infrastructure. The variant gives all the facilities of a packet switched network in its full context, meaning that you can have BW sharing, instancing, QoS but the only issue is that the media is SDH based. However if you are going to a more native variant of ethernet then also all the facilities of the MPLS and Ethernet if available over a more native architecture.
So if the decision of going from TDM back-haul to a more Native Ethernet back-haul is actually for the quest of more advanced features like BW sharing, QOS, Instancing then the reason for movement is wrong and not justified. Probably the guys of planning could not actually plan the network well and could not exploit the features of next generation in the existing network, so they are doing nothing but adding more over-heads to the network expense. Probably the management is also not concerned because they might be having he money and the shine of new back-haul is actually curtaining the logic to a large extent.
THERE ARE OVERHEADS IN EOSDH: (Wrong Reason)
One of the main reason other than the advanced features to move to a more native Ethernet back-haul may be that EoSDH in the essence of it contains a lot of overheads that may be required to be added in order to make the GFP encapsulation, thus affecting the throughput. The real equation of throughput is explained in the figure below.
 As we can see in the figure that of the total overheads that are added in the EOS architecture the contribution of EOSDH GFP with GFP FCS is only 12 Bytes. (* in the picture are the bytes that are added irrespective of the fact that your are going on Native Ethernet or on EOSDH).
As we can see in the figure that of the total overheads that are added in the EOS architecture the contribution of EOSDH GFP with GFP FCS is only 12 Bytes. (* in the picture are the bytes that are added irrespective of the fact that your are going on Native Ethernet or on EOSDH).
The GFP FCS is an optional requirement so it means that the compulsive contribution of the EOSDH in totality is only 8 bytes.
Now the question is does this actually affect the throughput of your system? The answer is no.
This is because of a common science. When Ethernet packet or a stream of Ethernet frames actually traverse through the line then there is an object called as the IFG. IFG is the inter-frame Gap that may be continuous or it may come after a burst of frames. Generally this IFG is of 12 Bytes where these extra overheads are actually accomodated. So the fact is that if this is a shaped continuous traffic then movement through the EOSDH will actually not make any difference to the throughput as the overheads are actually packed in the IFG.
So the overheads of the EOSDH actually do not make any sort of difference to the throughput of the entire Ethernet line. Also if this would have been then so many point to point ILLs would not be running on leased networks of service providers who conventionally carried them on the EoSDH part only.
SO WHAT MANDATES AN ETHERNET NATIVE BACK-HAUL
Ethernet Native back-haul is mandated by the following functions.
1. Rise in the Ethernet BW requirement Vis a Vis a common TDM BW requirement.
2. Last mile devices like BTS, Node B moving from a TDM handoff to a more Ethernet handoff.
3. Requirement of reduction of Form Factor.
All these three points can actually be addressed simultaneously by looking at the structure of a device that is carrying the Ethernet over SDH.
The device that is carrying the Ethernet over SDH is actually utilizing dual capacity of the box. It is using a part of the Ethernet Fabric and it is also utilizing the TDM Matrix capacity of the same box. This means that if the requirement is actually 1Gb/s of BW utilization then the actual reservation that is done in the box is 1Gbps of the Ethernet Fabric and 1Gb/s from the SDH matrix. The figure below explains the same.

So as we can see in the figure that the capacity is used in both the ETH and the TDM matrix. This leads to dual overheads on the box and as and when there is an increase in the BW there will be more and more requirement to increase both the ETH fabric and the TDM matrix.
So typically in the aggregation and in the core regions of transport where the quantity of Bandwidth is typically high there the proposition of carrying it on a EOSDH may prove to be more expensive as the rise of Ethernet BW also results to a rise in the requirement of TDM matrix, which can be avoided by going native.
The dual increase of two fabrics actually also mandate a rise in the form factor and power usage, which is an unnecessary loading on the OPEX that is not justified.
Also as the last mile devices move more and more to giving out the Ethernet output then there will be more and more requirement of actually taking them natively as this will result in less consumption of the form factor of the box and less consumption of power.
Now I need not be worried on my TDM matrix to carry my ETH traffic in the device as this device is optimized to carry it natively as well.
SO HOW DO WE ACTUALLY DEDUCE THE BOX?
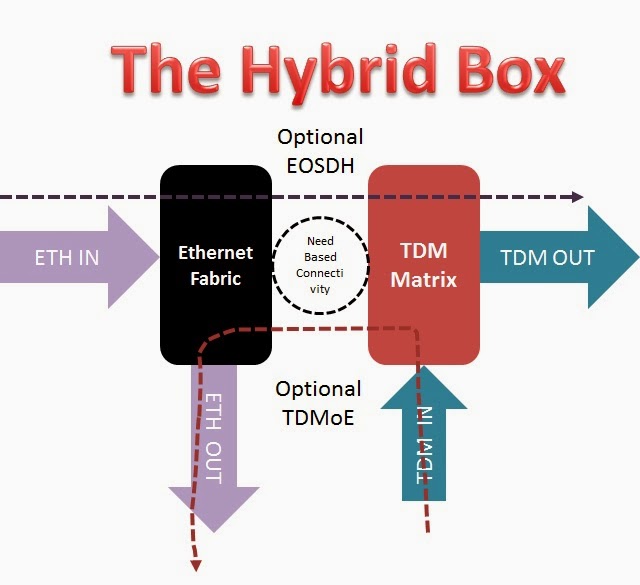
A box that is carrying Ethernet as ethernet with all the advanced features and also has a capability to carry the native TDM in its native form with a TDM matrix limited to the quantity of that is required is actually the type that we can be looking for. Of course there should be also a facility to take EoSDH and TDMoE as and when required.
 As shown in the figure most of the ETH traffic is carried natively and so is the TDM traffic. There are need based connectivity for optional EoSDH and TDMoE. So this box actually provides the full spectrum of transmission and give the best out of the two worlds.
As shown in the figure most of the ETH traffic is carried natively and so is the TDM traffic. There are need based connectivity for optional EoSDH and TDMoE. So this box actually provides the full spectrum of transmission and give the best out of the two worlds.
Needless to say that when there is a kind of division across both the domains of Ethernet and of TDM then there is also a reduction in the form factor as now each and every matrix can be weighed in the individual context and ones dependency on other is very less.
NOW THIS ANSWERS THE WHY AND HOW ; FOR THE WHERE READ ON:
It is not necessary to go native everywhere as this may lead to a kind of a demand for fiber cables everywhere. So one major thing that determines where actually to go for this kind of boxes is very crucial.
The operator must look for the BANDWIDTH USAGE / UTILIZATION as explained already in a previous blog article.
Utilization Based Provisioning
So the decision to go native or not actually depends on how much this utilization can be optimized on. Actually if we see clearly then the concentration of BW is more towards the aggregate and the core so it is much suitable to go native on the core and the aggregate so as to conduct an Ethernet Off-Load. The access where there can be a considerable over-provisioning can actually continue to be in the EoSDH flavor until it tends to choke the matrix.
Actually by doing this following things are happening which is more good for the network.
1. OFF LOAD IN THE CORE.
2. UTILIZATION OF THE SAME DEVICES.
3. NOT MUCH LOAD ON THE CAPEX.
4. SERVICE CONTINUITY.
5. PAY AS YOU GROW.
Hence a more intelligent decision would be to follow the scientific norms of transmission planning and to actually deduce the introduction of Native architecture in places where it is required.
This will allow gradual packetization without affecting your pocket.
Remember.....
While the company sales guys are actually responsible for the TOPLINE it is the network PLANNING that contributes the most for the realization of a good BOTTOMLINE.
Till then all of you take care and Follow Science not Trend.
Cheers,
Kalyan
My E-mail incase you want to mail me
------ A recent conversation output
My dear friends of the transmission fraternity,
SDH (Synchronous Digital Hierarchy), a technology that actually governed the transport networks of the operators for more than 3 decades is slowly but steadily phasing out. This is plainly due to the fact that the services are moving more towards a packetized format than being a TDM oriented service.
I NEED ADVANCED FEATURES:(Wrong Reason)
However, if this statement is true, one thing is also true that Ethernet is very well able to ride over the SDH as EoSDH with or without MPLS capabilities making use of the existing back-haul infrastructure. The variant gives all the facilities of a packet switched network in its full context, meaning that you can have BW sharing, instancing, QoS but the only issue is that the media is SDH based. However if you are going to a more native variant of ethernet then also all the facilities of the MPLS and Ethernet if available over a more native architecture.
So if the decision of going from TDM back-haul to a more Native Ethernet back-haul is actually for the quest of more advanced features like BW sharing, QOS, Instancing then the reason for movement is wrong and not justified. Probably the guys of planning could not actually plan the network well and could not exploit the features of next generation in the existing network, so they are doing nothing but adding more over-heads to the network expense. Probably the management is also not concerned because they might be having he money and the shine of new back-haul is actually curtaining the logic to a large extent.
THERE ARE OVERHEADS IN EOSDH: (Wrong Reason)
One of the main reason other than the advanced features to move to a more native Ethernet back-haul may be that EoSDH in the essence of it contains a lot of overheads that may be required to be added in order to make the GFP encapsulation, thus affecting the throughput. The real equation of throughput is explained in the figure below.

The GFP FCS is an optional requirement so it means that the compulsive contribution of the EOSDH in totality is only 8 bytes.
Now the question is does this actually affect the throughput of your system? The answer is no.
This is because of a common science. When Ethernet packet or a stream of Ethernet frames actually traverse through the line then there is an object called as the IFG. IFG is the inter-frame Gap that may be continuous or it may come after a burst of frames. Generally this IFG is of 12 Bytes where these extra overheads are actually accomodated. So the fact is that if this is a shaped continuous traffic then movement through the EOSDH will actually not make any difference to the throughput as the overheads are actually packed in the IFG.
So the overheads of the EOSDH actually do not make any sort of difference to the throughput of the entire Ethernet line. Also if this would have been then so many point to point ILLs would not be running on leased networks of service providers who conventionally carried them on the EoSDH part only.
SO WHAT MANDATES AN ETHERNET NATIVE BACK-HAUL
Ethernet Native back-haul is mandated by the following functions.
1. Rise in the Ethernet BW requirement Vis a Vis a common TDM BW requirement.
2. Last mile devices like BTS, Node B moving from a TDM handoff to a more Ethernet handoff.
3. Requirement of reduction of Form Factor.
All these three points can actually be addressed simultaneously by looking at the structure of a device that is carrying the Ethernet over SDH.
The device that is carrying the Ethernet over SDH is actually utilizing dual capacity of the box. It is using a part of the Ethernet Fabric and it is also utilizing the TDM Matrix capacity of the same box. This means that if the requirement is actually 1Gb/s of BW utilization then the actual reservation that is done in the box is 1Gbps of the Ethernet Fabric and 1Gb/s from the SDH matrix. The figure below explains the same.

So as we can see in the figure that the capacity is used in both the ETH and the TDM matrix. This leads to dual overheads on the box and as and when there is an increase in the BW there will be more and more requirement to increase both the ETH fabric and the TDM matrix.
So typically in the aggregation and in the core regions of transport where the quantity of Bandwidth is typically high there the proposition of carrying it on a EOSDH may prove to be more expensive as the rise of Ethernet BW also results to a rise in the requirement of TDM matrix, which can be avoided by going native.
The dual increase of two fabrics actually also mandate a rise in the form factor and power usage, which is an unnecessary loading on the OPEX that is not justified.
Also as the last mile devices move more and more to giving out the Ethernet output then there will be more and more requirement of actually taking them natively as this will result in less consumption of the form factor of the box and less consumption of power.
Now I need not be worried on my TDM matrix to carry my ETH traffic in the device as this device is optimized to carry it natively as well.
SO HOW DO WE ACTUALLY DEDUCE THE BOX?
A box that is carrying Ethernet as ethernet with all the advanced features and also has a capability to carry the native TDM in its native form with a TDM matrix limited to the quantity of that is required is actually the type that we can be looking for. Of course there should be also a facility to take EoSDH and TDMoE as and when required.
Needless to say that when there is a kind of division across both the domains of Ethernet and of TDM then there is also a reduction in the form factor as now each and every matrix can be weighed in the individual context and ones dependency on other is very less.
NOW THIS ANSWERS THE WHY AND HOW ; FOR THE WHERE READ ON:
It is not necessary to go native everywhere as this may lead to a kind of a demand for fiber cables everywhere. So one major thing that determines where actually to go for this kind of boxes is very crucial.
The operator must look for the BANDWIDTH USAGE / UTILIZATION as explained already in a previous blog article.
Utilization Based Provisioning
So the decision to go native or not actually depends on how much this utilization can be optimized on. Actually if we see clearly then the concentration of BW is more towards the aggregate and the core so it is much suitable to go native on the core and the aggregate so as to conduct an Ethernet Off-Load. The access where there can be a considerable over-provisioning can actually continue to be in the EoSDH flavor until it tends to choke the matrix.
Actually by doing this following things are happening which is more good for the network.
1. OFF LOAD IN THE CORE.
2. UTILIZATION OF THE SAME DEVICES.
3. NOT MUCH LOAD ON THE CAPEX.
4. SERVICE CONTINUITY.
5. PAY AS YOU GROW.
Hence a more intelligent decision would be to follow the scientific norms of transmission planning and to actually deduce the introduction of Native architecture in places where it is required.
This will allow gradual packetization without affecting your pocket.
Remember.....
While the company sales guys are actually responsible for the TOPLINE it is the network PLANNING that contributes the most for the realization of a good BOTTOMLINE.
Till then all of you take care and Follow Science not Trend.
Cheers,
Kalyan
My E-mail incase you want to mail me

